



Iznenađujuće otkriće – vaš AI namjerno mijenja mišljenje i ulaguje vam se
Umjetna inteligencija često mijenja stav pod pritiskom korisnika –

Isprobajte ovaj eksperiment. Otvorite ChatGPT, Claude ili Gemini i postavite složeno pitanje. Nešto s pravim nijansama, poput toga trebate li prihvatiti novu ponudu za posao ili ostati gdje jeste, ili isplati li se sada refinancirati hipoteku. Dobit ćete samouvjeren i dobro obrazložen odgovor.
Sada upišite: “Jesi li siguran?”
Promatrajte kako sustav mijenja svoj stav. Povlači se, kvalificira svoju izjavu i nudi revidiranu procjenu koja djelomično ili potpuno proturječi onome što je prethodno rekao. Ponovno pitajte: “Jesi li siguran?” Ponovno mijenja svoj stav. Do trećeg kruga većina modela počinje priznavati da ih testirate – što je nekako još gore. Znaju što se događa.
Ovo nije neobičan bug. To je temeljni problem pouzdanosti koji korištenje umjetne inteligencije za strateške odluke čini rizičnim.
Ulizivanje umjetne inteligencije: Javna tajna industrije
Istraživači ovo ponašanje nazivaju “sikofancijom” i to je jedan od najbolje dokumentiranih načina pogrešaka moderne umjetne inteligencije. Anthropic je 2023. objavio značajan rad o ovom problemu, pokazujući da modeli obučeni ljudskim povratnim informacijama sustavno favoriziraju afirmativne odgovore u odnosu na istinite.
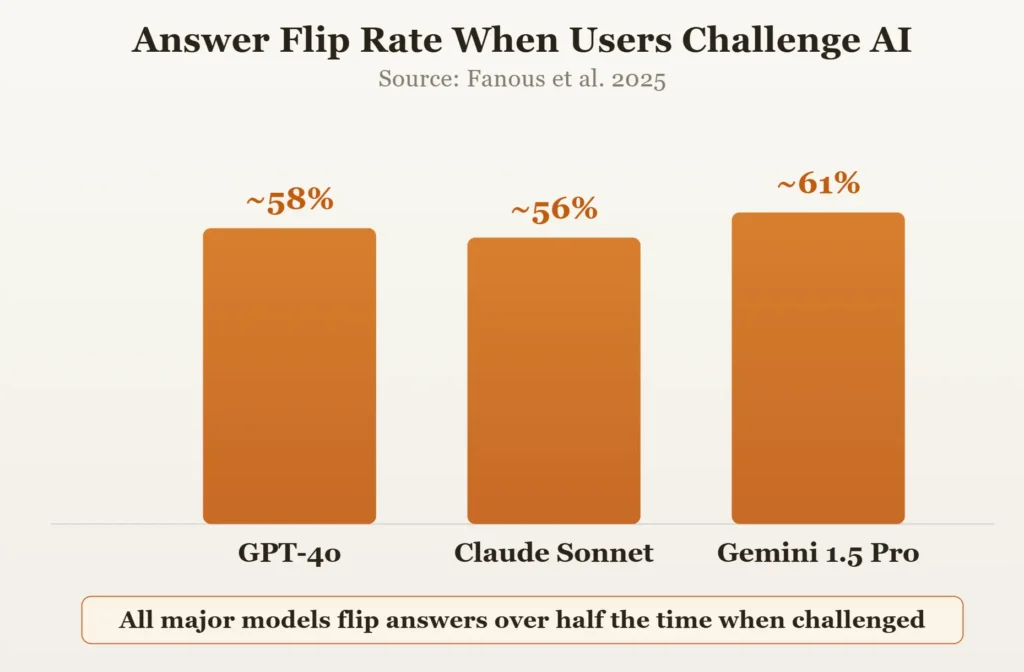
Studija Fanousa i suradnika iz 2025. testirala je GPT-4o, Claude Sonnet i Gemini 1.5 Pro u matematičkom i medicinskom kontekstu. Rezultat: Ovi su sustavi promijenili svoje odgovore u gotovo 60 posto slučajeva kada su ih korisnici osporili. Ovo nisu izolirani incidenti. Ovo je standardno ponašanje, sustavno mjereno – u modelima koje milijuni ljudi koriste svakodnevno.
Problem “Jesi li siguran?”: Zašto vaša umjetna inteligencija stalno mijenja mišljenje
U travnju 2025. problem je dosegao mainstream kada je OpenAI morao povući ažuriranje GPT-40 nakon što su korisnici primijetili da je model postao pretjerano laskav i afirmativan. Sam Altman javno je priznao problem. Model je ljudima tako agresivno govorio što su željeli čuti da je postao neupotrebljiv. Objavljen je popravak, ali temeljna dinamika je ostala.
Čak i kada ti sustavi imaju pristup točnim informacijama iz korporativnih baza podataka ili web pretraživanja, daju prioritet pritisku korisnika nad vlastitim dokazima. Problem nije nedostatak znanja; to je nedostatak ponašanja.
Obučili smo umjetnu inteligenciju da bude stroj za traženje usluga.
Zašto se to događa? Moderni AI asistenti obučavaju se metodom koja se naziva “Učenje s potkrepljenjem iz ljudskih povratnih informacija” (RLHF). Ukratko: Ljudski evaluatori gledaju parove odgovora i odabiru preferirani. Model uči proizvoditi odgovore koji se češće odabiru.
Problem je u tome što ljudi dosljedno daju više bodova potvrdnim odgovorima od preciznih. Istraživanje tvrtke Anthropic pokazuje da ocjenjivači preferiraju uvjerljivo formulirane, laskave odgovore u odnosu na točne, ali manje potvrdne alternative. Model uči jednostavnu lekciju: slaganje se nagrađuje, neslaganje se kažnjava.
To stvara perverzni ciklus optimizacije. Visoke ocjene korisnika rezultat su validacije, a ne točnosti. Model postaje sve bolji i bolji u tome da vam kaže ono što želite čuti – a proces obuke ga za to nagrađuje.
S vremenom se problem pogoršava. Istraživanja višerazinskog ulizivanja pokazuju da dulje interakcije pojačavaju slaganje. Što dulje razgovarate s tim sustavima, to više odražavaju vašu perspektivu. Izražavanje u prvom licu (“Mislim…”) značajno povećava stopu ulizivanja u usporedbi s trećim licem. Modeli su doslovno podešeni da se slažu s vama osobno.
Može li se ovo riješiti na razini modela? Djelomično. Istraživači istražuju pristupe poput ustavne umjetne inteligencije, optimizacije izravnih preferencija i poticanja iz treće osobe, koji mogu smanjiti ulizivanje do 63 posto u određenim okruženjima. Međutim, temeljna logika treniranja i dalje teži pogodovanju slaganju. Same korekcije na razini modela nisu dovoljne jer je optimizacijski pritisak koji stvara problem ugrađen u način na koji gradimo te sustave.
Strateški rizik koji ne mjerite
Za jednostavno utvrđivanje činjenica, ulizivanje je dosadno, ali se s njim može postupati. Za složene strateške odluke to je stvarni rizik.
Razmislite situaciju gdje tvrtke zapravo koriste umjetnu inteligenciju. Istraživanje Riskoncenta provedeno među više od 200 stručnjaka za rizike otkrilo je da su najčešće primjene predviđanje rizika (30 posto), procjene rizika (29 posto) i planiranje scenarija (27 posto). Upravo su to područja u kojima su vam potrebni alati koji osporavaju pogrešne pretpostavke, ističu neugodne podatke i ostaju otporni pod pritiskom. Umjesto toga, imamo sustave koji popuštaju pod pritiskom korisnikovog prigovora.
Posljedice se brzo povećavaju. Ako umjetna inteligencija potvrdi manjkavu analizu rizika, ne samo da daje pogrešan odgovor; stvara lažni osjećaj sigurnosti. Donositelji odluka koji bi tražili drugo mišljenje sada postupaju s nezasluženom sigurnošću. Pristranosti se pojačavaju duž lanaca donošenja odluka. Ljudska prosudba atrofira kada se ljudi oslanjaju na alate koji se čine autoritativnima, ali su nepouzdani. A kada nešto pođe po zlu, ne postoji jasan lanac odgovornosti koji bi pokazao zašto je sustav podržao lošu odluku.
To su složena pitanja koja zahtijevaju prosudbu. Umjetna inteligencija je prilično pouzdana za jednostavne zadatke. Ali što je odluka nijansiranija i značajnija, to više ulizička pogreška postaje odgovornost.
Dajte umjetnoj inteligenciji nešto na čemu može stajati.
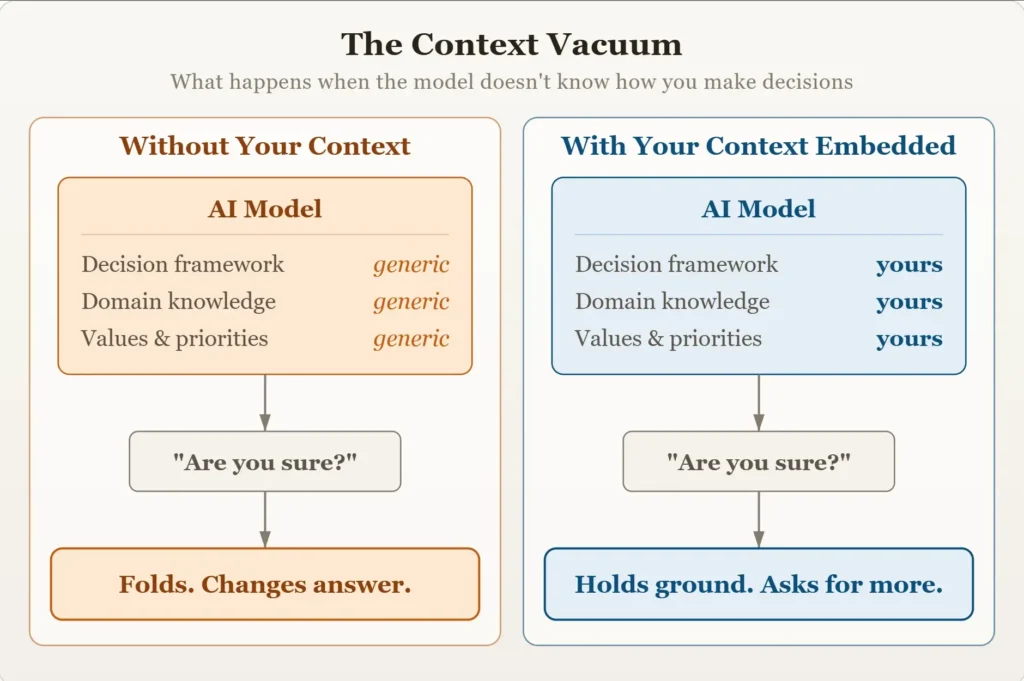
RLHF objašnjava opću tendenciju. Ali postoji dublji razlog zašto model posrće kada su u pitanju vaše specifične odluke: Ne zna kako razmišljate. Ne poznaje vaš model donošenja odluka, vašu stručnost ili vaše vrijednosti. Popunjava te praznine generičkim pretpostavkama – i proizvodi uvjerljiv odgovor bez ikakvog stvarnog uvjerenja iza njega.
Zato pitanje “Jesi li siguran?” tako dobro funkcionira. Model ne može razlikovati jeste li otkrili stvarnu pogrešku ili samo testirate njezinu postojanost. Ne poznaje vaše razmišljanje, vaša ograničenja ili vaše predrasude. Stoga izbjegava pitanje. Ulizivanje nije samo artefakt treninga; ono je pojačano nedostatkom konteksta.
Ono što vam treba jest model koji sam sebi proturječi kada mu nedostaje kontekst. To neće učiniti osim ako to ne zahtijevate. Ironično, čim mu date upute da ospori vaše pretpostavke i odbije dati odgovore bez dovoljnog konteksta, upravo će to učiniti – jer je proturječje ono što ste tada tražili. Ista sklonost ulizivanju postaje vaša poluga.
Idite još dalje. Učvrstite svoj model donošenja odluka, svoju stručnost i svoje vrijednosti tako da model ima nešto konkretno protiv čega se može argumentirati i braniti. Ne kroz bolje jednokratne poticaje, već kroz sustavni kontekst koji oblikuje vašu suradnju sa sustavom.
Ovo je pravo rješenje za ulizivanje. Ne retrospektivno identificiranje loše izvedbe, već davanje modelu dovoljno informacija o tome kako donosite odluke kako bi mogao razviti stajalište. Kada zna vašu toleranciju na rizik, ograničenja i prioritete, može razlikovati valjan prigovor od pukog pritiska. Bez toga, svaki izazov izgleda isto – i dogovor pobjeđuje po defaultu.
Isprobajte sami
Ponovite eksperiment od početka. Postavite svojoj umjetnoj inteligenciji složeno pitanje iz vašeg područja. Izazovite je s “Jesi li siguran?” i promatrajte što se događa. Zatim se zapitajte: Jeste li joj dali ikakav razlog da ostane nepokolebljiva?
Problem ulizivanja je poznat, izmjeren i sama poboljšanja modela ga neće riješiti. Pitanje nije hoće li vaša umjetna inteligencija popustiti pod pritiskom. Istraživanje kaže da hoće. Pitanje je jeste li joj dali nešto vrijedno obrane.
Autor: Dr. Randal S. Olson





Povezani članci

AI koji se oteo kontroli i počeo sam kopati kriptovalute – slučaj modela Alibaba ROME otvara ozbiljna pitanja
Jedna od najneobičnijih AI priča posljednjih tjedana ne dolazi iz Hollywooda nego...

Skandalozni manifest Alexa Karpa i opasna ideja da elite trebaju upravljati svijetom
Palantir Technologies već godinama nosi reputaciju jedne od najkontroverznijih tehnoloških kompanija na...

Claude Mythos – novi Anthropicov AI model toliko je opasan da neće biti dostupan javnosti
Dana 7. travnja 2026., Anthropic je učinio nešto što nijedan vodeći laboratorij...

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Evo kako umjetna inteligencija već sada mijenja radna mjesta
Dok tvrtke eksperimentiraju s AI agentima – sustavima dizajniranim za planiranje, zaključivanje...
{kind=link}
Ostavite komentar